Can human identify AI-generated (fake) videos and provide grounded reasons?
While video generation models have advanced rapidly, a critical dimension –
whether human can detect deepfake traces within a generated video, i.e., spa-
tiotemporal grounded visual artifacts that reveal a video as machine generated –
has been largely overlooked.
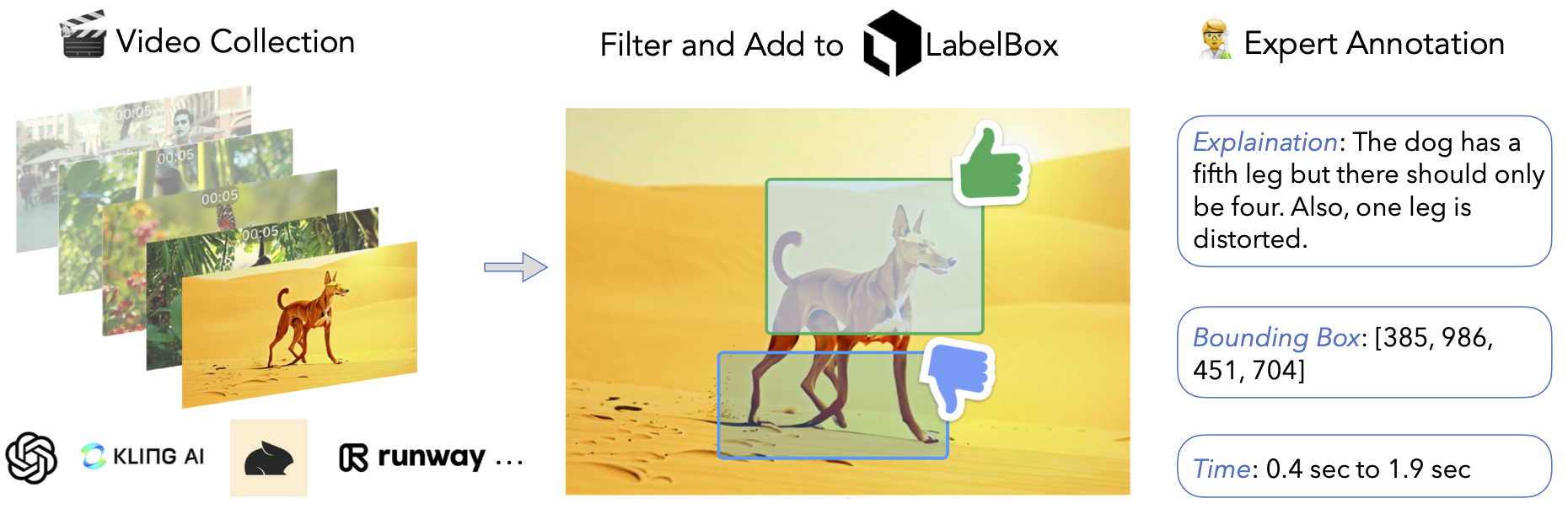
We introduce DEEPTRACEREWARD, the first fine-
grained, spatially and temporally aware benchmark that annotates human-perceived
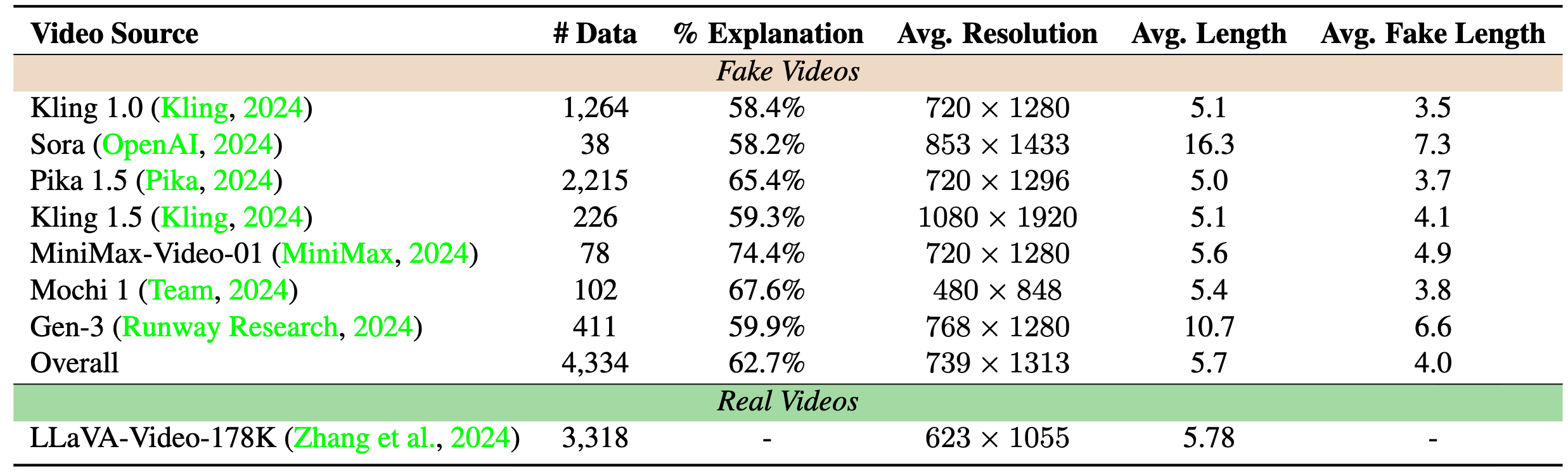
fake traces for video generation reward. The dataset comprises 4.3K detailed
annotations across 3.3K high-quality generated videos. Each annotation provides
a natural-language explanation, pinpoints a bounding-box region containing the
perceived trace, and marks precise onset and offset timestamps.
We consolidate these annotations into 9 major categories of deepfake traces that lead humans to
identify a video as AI-generated, and train multimodal language models (LMs)
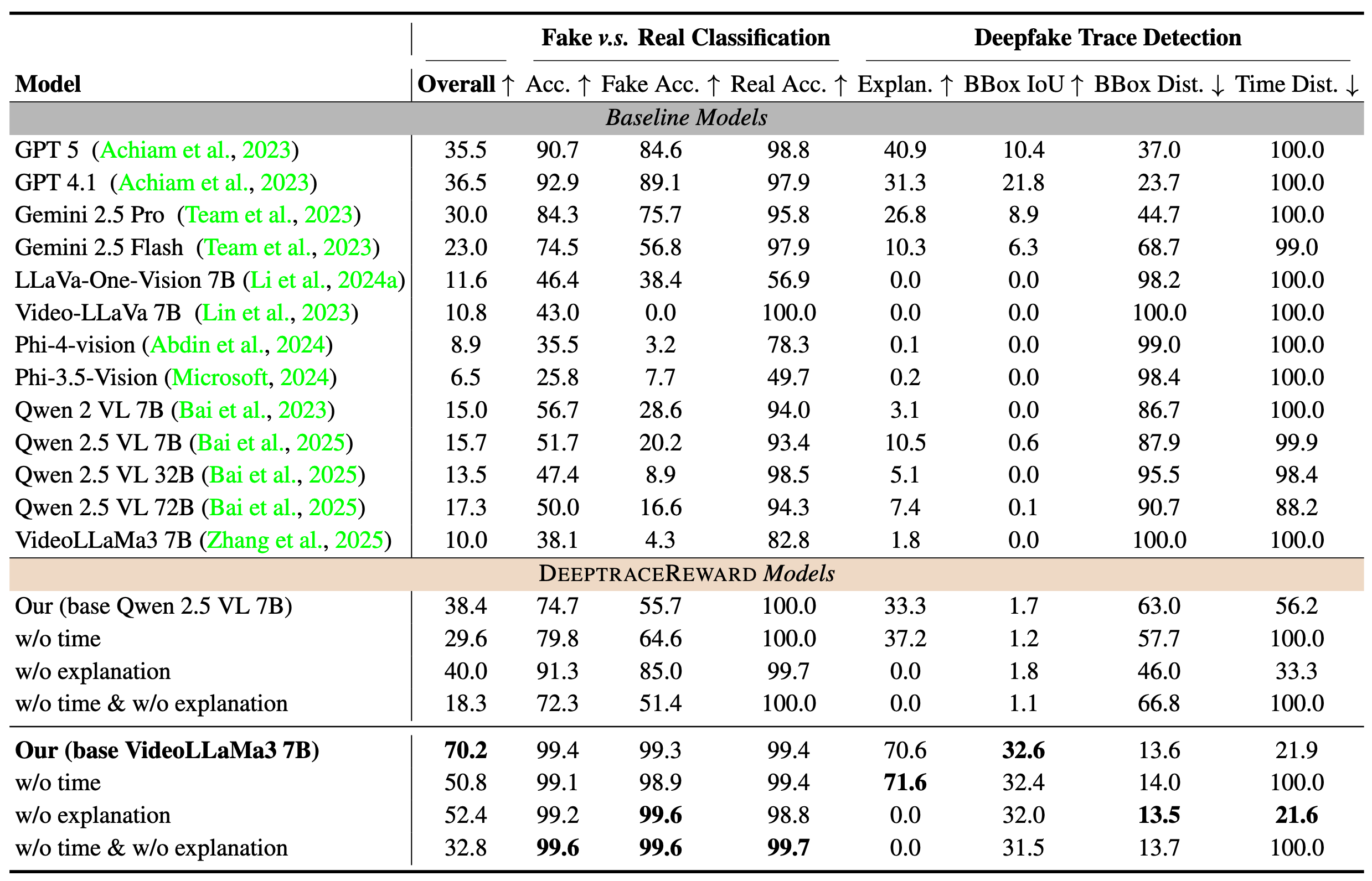
as reward models to mimic human judgments and localizations. On DEEPTRAC-
EREWARD, our 7B reward model outperforms GPT-5 by 34.7% on average across
fake clue identification, grounding, and explanation.
Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially
easier than fine-grained deepfake trace detection; within the latter, performance
degrades from natural language explanations (easiest), to spatial grounding, to
temporal labeling (hardest). By foregrounding human-perceived deepfake traces,
DEEPTRACEREWARD provides a rigorous testbed and training signal for socially
aware and trustworthy video generation.
 DeeptraceReward: Learning Human-Perceived Fakeness in Generated Videos with Multimodal LLMs
DeeptraceReward: Learning Human-Perceived Fakeness in Generated Videos with Multimodal LLMs
 𝒑
𝒑 𝒔
𝒔